| Map
> Problem Definition > Data
Preparation > Data Exploration
> Modeling > Evaluation
> Deployment |
|
|
|
|
Data Preparation
|
| Data preparation is about constructing a dataset from
one or more data
sources to be used for exploration and modeling. It is a solid practice to
start with an initial dataset to get familiar with the data, to discover
first insights into the data and have a good understanding of any possible
data quality issues. Data preparation is often a time consuming process and heavily
prone to errors. The old saying "garbage-in-garbage-out" is particularly applicable to
those data science projects where data gathered with many invalid, out-of-range
and missing values. Analyzing data that has not been carefully screened for such problems can produce highly misleading
results.
Then, the success of data science projects heavily depends on the quality
of the prepared data.
|
| |
|
|
| |
|
|
Data
|
|
|
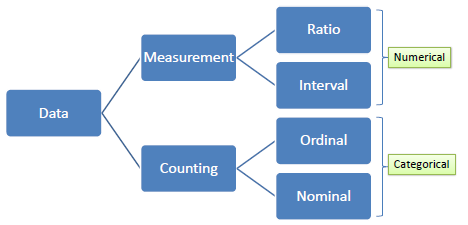
| Data is information typically the results of measurement
(numerical) or counting (categorical). Variables serve as
placeholders for data. There are two types of variables, numerical
and categorical.
A numerical or continuous variable
is one that can accept any value within a finite or infinite interval (e.g.,
height, weight, temperature, blood glucose, ...). There are two
types of numerical data, interval and ratio. Data on an interval scale can be added and subtracted but cannot
be meaningfully multiplied or divided because there is no true zero. For example, we cannot say that one
day is twice as hot as another day. On the other hand, data on a ratio
scale has true zero and can be added, subtracted, multiplied or divided
(e.g., weight).
A categorical or discrete variable
is one
that can accept two or more values (categories). There are two types of categorical
data, nominal and ordinal. Nominal data does not have
an intrinsic ordering in the categories. For example, "gender"
with two categories, male and female. In
contrast, ordinal data does have an intrinsic ordering in the categories. For example,
"level of energy" with three orderly
categories (low, medium and high). |
|
|
|
|
|
|
| |
|
|
| |
|
|
Dataset
|
|
|
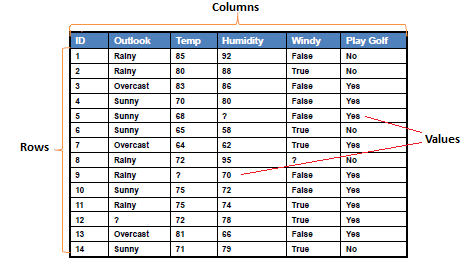
| Dataset is a collection of data, usually presented in
a tabular form. Each column represents a particular variable, and each row corresponds to a given member of the data. |
|
|
|
|
|
|
| There are some alternatives for
columns, rows and values. |
|
|
- Columns, Fields, Attributes, Variables
- Rows, Records, Objects, Cases, Instances,
Examples, Vectors
- Values, Data
|
|
|
| In predictive modeling, predictors or
attributes are the input variables and target or class
attribute is the output variable whose value is determined by the values of
the predictors and function of the predictive model. |
|
|
| |
|
|
| |
|
|
Database
|
|
|
| Database collects, stores and manages information so users can retrieve, add, update or remove such information.
It presents information in tables with rows and columns. A table is referred to as a relation in the sense that it is a collection of objects of the same type (rows). Data in a table can be related according to common keys or concepts, and the ability to retrieve related data from
related tables is the basis for the term relational database. A Database Management System
(DBMS) handles the way data is stored, maintained, and retrieved.
Most data science toolboxes connect to databases through ODBC (Open Database Connectivity)
or JDBC (Java Database Connectivity) interfaces. |
|
|
|
 |
|
|
|
SQL (Structured Query Language) is a database computer language for managing
and manipulating data in relational database management systems (RDBMS). |
|
|
|
|
|
|
|
SQL Data Definition Language (DDL) permits database tables to be created, altered or deleted. We can also define indexes (keys), specify links between tables, and impose constraints between database tables.
-
CREATE TABLE : creates a new table
-
ALTER TABLE : alters a table
-
DROP TABLE : deletes a table
-
CREATE INDEX : creates an index
-
DROP INDEX : deletes an index
|
|
|
SQL Data Manipulation Language (DML)
is a language which enables users to access and manipulate data.
- SELECT : retrieval of data from the database
- INSERT INTO : insertion of new data into the
database
- UPDATE : modification of data in the database
- DELETE : deletion of data in the database
|
|
|
| |
|
|
ETL (Extraction, Transformation
and Loading)
|
|
|
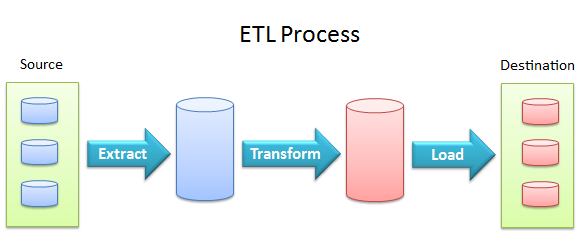
ETL extracts data from data sources
and loads it into data destinations using a set of transformation
functions.
- Data extraction provides the ability to extract data from a variety of data sources, such as flat
files, relational databases, streaming data, XML files, and ODBC/JDBC data sources.
- Data transformation provides the ability to
cleanse, convert, aggregate, merge, and split data.
- Data loading provides the ability to load data into
destination databases via update, insert or delete statements, or in bulk.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|