| Map
> Data Science > Predicting the Future >
Modeling > Classification
> Decision Tree > Super Attributes |
|
|
|
|
|
|
Decision Tree -
Super Attributes
|
|
|
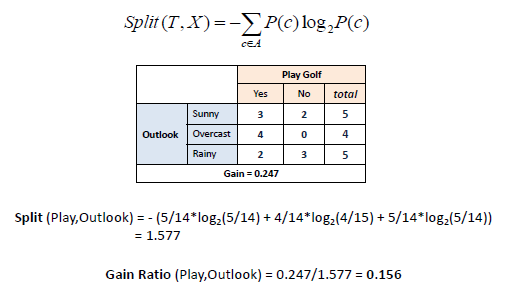
| The information gain equation, G(T,X) is biased toward attributes that have a large number of values over attributes that have a smaller number of values.
These ‘Super Attributes’ will easily be selected as the root, resulted in a broad tree that classifies perfectly but performs poorly on unseen instances.
We can penalize attributes with large numbers of values by using an alternative method for attribute selection, referred to as
Gain Ratio. |
|
|
| |
|
|
|

|
|
|
| Example: |
|
|
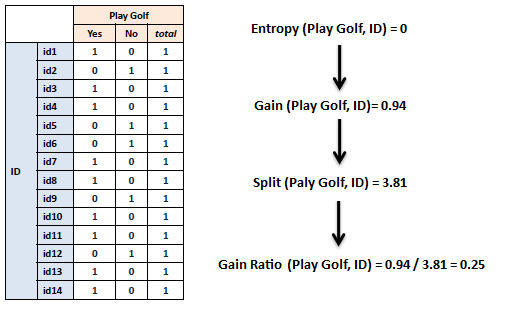
| The following example shows a frequency table
between the target (Play Golf) and the ID attribute which has a unique
value for each record of the dataset. |
|
|
| |
|
|
|
|
|
|
| The information gain for ID is
maximum (0.94) without using the split information. However, with the adjustment the information gain dropped to 0.25. |
|
|
|
|
|