K Nearest Neighbors - Regression


D = Sqrt[(48-33)^2 + (142000-150000)^2] = 8000.01 >> HPI = 264
HPI = (264+139+139)/3 = 180.7
Standardized Distance
| Exercise |  |
| Map > Data Science > Predicting the Future > Modeling > Regression > K Nearest Neighbors | |||||
K Nearest Neighbors - Regression |
|||||
| K nearest neighbors is a simple algorithm that stores all available cases and predict the numerical target based on a similarity measure (e.g., distance functions). KNN has been used in statistical estimation and pattern recognition already in the beginning of 1970’s as a non-parametric technique. | |||||
| Algorithm | |||||
| A simple implementation of KNN regression is to calculate the average of the numerical target of the K nearest neighbors. Another approach uses an inverse distance weighted average of the K nearest neighbors. KNN regression uses the same distance functions as KNN classification. | |||||
|
|
|||||
| The above three distance measures are only valid for continuous variables. In the case of categorical variables you must use the Hamming distance, which is a measure of the number of instances in which corresponding symbols are different in two strings of equal length. | |||||
|
|
|||||
| Choosing the optimal value for K is best done by first inspecting the data. In general, a large K value is more precise as it reduces the overall noise; however, the compromise is that the distinct boundaries within the feature space are blurred. Cross-validation is another way to retrospectively determine a good K value by using an independent data set to validate your K value. The optimal K for most datasets is 10 or more. That produces much better results than 1-NN. | |||||
| Example: | |||||
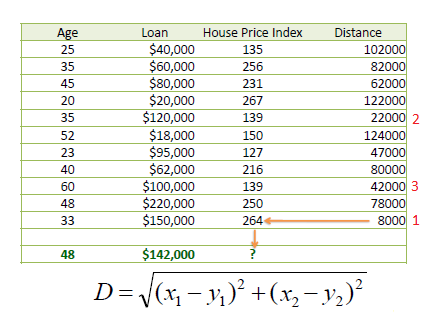
| Consider the following data concerning House Price Index or HPI. Age and Loan are two numerical variables (predictors) and HPI is the numerical target. | |||||
|
|
|||||
| We can now use the training set to classify an unknown case (Age=33 and Loan=$150,000) using Euclidean distance. If K=1 then the nearest neighbor is the last case in the training set with HPI=264. | |||||
|
D = Sqrt[(48-33)^2 + (142000-150000)^2] = 8000.01 >> HPI = 264 |
|||||
| By having K=3, the prediction for HPI is equal to the average of HPI for the top three neighbors. | |||||
|
HPI = (264+139+139)/3 = 180.7 |
|||||
|
|
|||||
|
Standardized Distance |
|||||
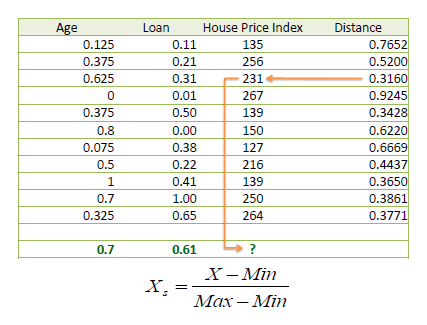
| One major drawback in calculating distance measures directly from the training set is in the case where variables have different measurement scales or there is a mixture of numerical and categorical variables. For example, if one variable is based on annual income in dollars, and the other is based on age in years then income will have a much higher influence on the distance calculated. One solution is to standardize the training set as shown below. | |||||
|
|
|||||
| As mentioned in KNN Classification using the standardized distance on the same training set, the unknown case returned a different neighbor which is not a good sign of robustness. | |||||
|
|||||