| Map
> Problem Definition > Data
Preparation > Data Exploration
> Modeling > Evaluation
> Deployment |
|
|
|
|
|
|
Model Deployment
|
|
|
| The concept of deployment in data science refers to the application of a model for prediction
using a new data. Building a model is generally not the end of the project. Even if the purpose of the model is to increase knowledge of the data, the knowledge gained will need to be organized and presented in a way that the customer can use it.
Depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data
science process.
In many cases, it will be the customer, not the data analyst, who will carry out the deployment steps.
For example, a credit card company may want to deploy a trained model or set of models (e.g., neural networks, meta-learner) to quickly identify transactions, which have a high probability of being fraudulent.
However, even if the analyst will not carry out the deployment effort it is important for the customer to understand up front what actions will need to be carried out in order to actually make use of the created models. |
|
|
|
|
|
|
| Model deployment methods: |
|
|
| In general, there is four way of deploying the
models in data science. |
|
|
- Data science tools
(or cloud)
- Programming
language (Java, C, VB, …)
- Database and SQL
script (TSQL, PL-SQL, …)
- PMML (Predictive Model Markup Language)
|
|
|
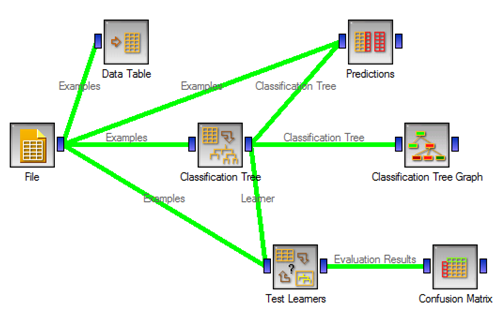
| An example of using a data mining tool (Orange) to
deploy a decision tree model. |
|
|
|
|
|
|
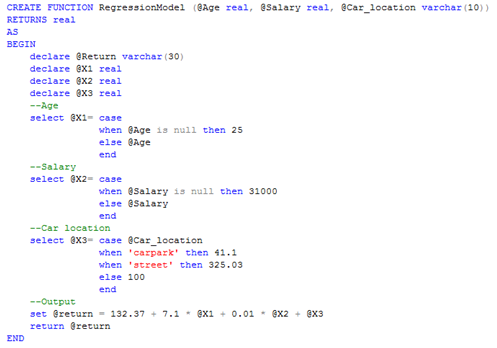
| An example of using a programming language (Visual
Basic) to deploy a regression model. |
|
|
|

|
|
|
| Same regression model deployed in the SQL script. |
|
|
|
|
|
|
| |
|
|
| Predictive Model Markup Language (PMML) |
|
|
| PMML is an XML-based language used to define statistical and data
science models and to share these between compliant applications.
It defines a standard not only to represent data-science models, but also data handling and data transformations (pre and post processing).
PMML is developed by DMG to avoid proprietary issues and incompatibilities and to deploy models.
PMML eliminates the need for custom model deployment and allows for the clear separation of model development
and model deployment tasks. The following data science methods are
supported by PMML. |
|
|
- Regression
- Neural Networks
- Support Vector Machines
- Decision Trees
- Naïve Bayes
- Clustering
- Sequences
- Rule Sets
- Association Rules
- Time-Series
- Text Models
|
|
|
| PMML Processes |
|
|
- Pre-Processing
- Data Dictionary: Allows for the explicit specification of valid, invalid and missing values.
- Mining Schema: Used to define the appropriate treatment to be applied to missing and invalid values.
- Transformations: Allow for variable discretization, normalization, and mapping with handling of missing and default values.
- Built-in Functions: Arithmetic expressions, handling of date and time as well as strings.
In addition, used for implementing IF-THEN-ELSE logic and Boolean operations.
- Models
- PMML allows for several predictive modeling techniques to be fully expressed.
- Post-Processing
- Scaling of model outputs can be performed with PMML element Targets.
|
|
|
| PMML Components |
|
|
| Header: contains general information about the PMML document, such as copyright information for the model, its description, and information about the application used to generate the model such as name and version.
It also contains an attribute for a timestamp which can be used to specify the date of model creation. |
|
|
|
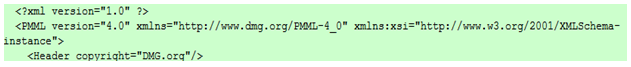
|
|
|
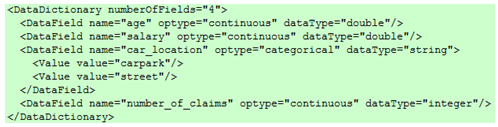
| Data Dictionary: contains definitions for all the possible fields used by the model. It is here that a field is defined as continuous, categorical, or ordinal.
Depending on this definition, the appropriate value ranges are then defined as well as the data type (such as, string or double). |
|
|
|
|
|
|
| Data Transformations: transformations allow for the mapping of user data into a more desirable form to be used by the mining model. PMML defines several kinds of simple data transformations. |
|
|
- Normalization: map values to numbers, the input can be continuous or discrete.
- Discretization: map continuous values to discrete values.
- Value mapping: map discrete values to discrete values.
- Functions: derive a value by applying a function to one or more parameters.
- Aggregation: used to summarize or collect groups of values.
|
|
|
|

|
|
|
| Model: contains the definition of the data science
model. For example a fee-forward neural network is represented in PMML by a "NeuralNetwork" element which contains attributes such as: |
|
|
- Model Name (attribute modelName)
- Function Name (attribute functionName)
- Algorithm Name (attribute algorithmName)
- Activation Function (attribute
activationFunction)
- Number of Layers (attribute numberOfLayers)
|
|
|
| Mining Schema: the mining schema lists all fields used in the model. This can be a subset of the fields as defined in the data dictionary. It contains specific information about each field, such as: |
|
|
- Name (attribute name): must refer to a field in the data dictionary
- Usage type (attribute usageType): defines the way a field is to be used in the model. Typical values are: active, predicted, and supplementary. Predicted fields are those whose values are predicted by the model.
- Outlier Treatment (attribute outliers): defines the outlier treatment to be use. In
PMML, outliers can be treated as missing values, as extreme values (based on the definition of high and low values for a particular field), or as is.
- Missing Value Replacement Policy (attribute
missingValueReplacement): if this attribute is specified then a missing value is automatically replaced by the given values.
- Missing Value Treatment (attribute
missingValueTreatment): indicates how the missing value replacement was derived (e.g. as value, mean or median).
|
|
|
|

|
|
|
| Targets: allow for post-processing of the predicted value in the format of scaling if the output of the model is continuous.
Targets can also be used for classification tasks. In this case, the attribute
prior Probability specifies a default probability for the corresponding target category. It is used if the prediction logic itself did not produce a result. This can happen, e.g., if an input value is missing and there is no other method for treating missing values. |
|
|
|

|
|
|
|
|
|
| PMML 4.0 – New Features |
|
|
- Improved Pre-Processing Capabilities
- Additions to built-in functions include a range of Boolean operations and an If-Then-Else function.
- Time Series Models
- New exponential Smoothing models; also place holders for ARIMA, Seasonal Trend Decomposition, and Spectral Analysis, which are to be supported in the near future.
- Model Explanation
- Saving of evaluation and model performance measures to the PMML file itself.
- Multiple Models
- Capabilities for model composition, ensembles, and segmentation (e.g., combining of regression and decision trees).
- Extensions of Existing Elements
- Addition of multi-class classification for Support Vector Machines, improved representation for Association Rules, and the addition of Cox Regression Models.
|
|
|
|
|
|